The Parallel Performance of Dynamo Simulations
Leeds Institute for Fluid Dynamics Deputy Director, Chris Davies, reports on the outcomes of his successful LIFD seedcorn funding award. These internal funding awards are intended to fund small pilot projects or networking activities that will develop new interdisciplinary collaborations and will lead to a more substantial research activity such as an externally funded grant application for staff involved in LIFD.
The Parallel Performance of Dynamo Simulations
The magnetic fields of planets, stars and galaxies are all generated by a dynamo process in which motion of fluid (e.g. liquid iron, plasma) provides the power that overcomes dissipative effects such as friction and electrical resistance. By relating the physics of the dynamo process to observed magnetic fields we can gain insight into the interior structure, dynamics and evolution of many remote objects that would be otherwise inaccessible.
This project focuses on the geodynamo process that generates Earth’s magnetic field 3000 km below the planet’s surface in the liquid iron core. The key fluid dynamical ingredients for the geodynamo are the (approximately) spherical geometry of the liquid core, the rapid planetary rotation, and the strong force applied by the magnetic field to the fluid. The interactions between flow, field, and the buoyancy source that drives the motions are represented by a coupled system of non-linear partial differential equations and so most work is conducted using parallel computer codes that run on large high-performance computing (HPC) resources. However, even when using thousands of CPUs, it is still impossible to replicate the physical conditions Earth’s core.
This seedcorn project investigates how to improve the parallel performance of the Leeds Dynamo Code dynamo code, LDC. LDC is uses spherical harmonics to represent the solution in colatitude and longitude and finite differences in radius. The solution is split across processors in 2 dimensions, radius and co-latitude. Time-stepping from an initial condition is performed using a predictor-corrector method. The rate-limiting part of the code is the transform between real and spectral space at each time step, which is required to evaluate the non-linear terms. Here we are interested in the performance benefits that can be accrued by tuning the code using its existing methodology. Since a standard run may involve tens of millions of timesteps, even small improvements in the performance per timestep can translate into significant decrease in overall runtime.
Analysis was conducted by Dr. Mark Richardson from the Centre for Environmental Modelling and Climate (CEMAC) within the School of Earth and Environment (SEE). The following tasks were performed:
Performance analysis: Here the aim was to establish how well the code is using the computational resources, identifying the “bottlenecks” and suggesting code refactoring to address issues During this process the consideration of upcoming novel hardware with attached accelerators is considered as an opportunity to enhance some of the provided solutions.
The main resource available for this work was the UK National Supercomputing Facility (Archer in 2020: www.archer.ac.uk soon to be Archer2). We used the vendor supplied tools, collectively known as CrayPAT, and in particular the “sample followed by tracing experiments” tool. The code executable was built and then instrumentation was automatically inserted, which provides human readable metrics and tabulation of information.
The figure below shows example performance analysis for a test case that requires 1536 cores (64 nodes of Archer) and was supplied for a 48-hour simulation run. This was reduced to 6000-timesteps to reduce time between simulation runs and each simulation was of order 25 minutes wall time. The analysis identified the following primary bottlenecks:
- Transform of variables between physical to spectral space (tra_qst2rtp);
- Waiting (mpi_wait) and data collection (mpi_allreduce) involved in parallel processing.
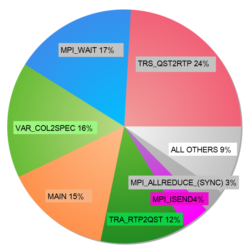
Based on this initial assessment the following improvements were tested (see summary table below):
Loop merging:
The preliminary sampling and tracing experiments indicated two specific routines accounting for 30% of the wall-time. Inspection showed them to have deeply nested loop structures that are repeated for each of the 3 “dimensions”. Merging the 3 independent loops allows improved compiler optimisation and will also aid any parallel acceleration of those loops with attendant GPUS or additional CPUs. Initial tests indicate a potentially significant performance boost can be obtained.
MPI_Allreduce
We investigated replacing MPI “all reduce” with an MPI “reduce” that arises in the process of writing diagnostic files to disk. This did not result in major performance improvement, which suggests that the Cray implementation of MPI_Allreduce is very efficient and the overhead of opening the text file to write a single line dominates. More work can be done it verify and propose the alternative of a dedicated asynchronous writer.
Double complex data structures for communication in MPI
There are some places where the packing of a communication buffer is potentially slower than it ought to be as a double complex number is being broken down to its real and imaginary components. These components are then inserted into the send buffer in an interleaved fashion. It may be more efficient to pack the reals and then the imaginary and then send. A method to avoid the separation of real and imaginary is to use the double complex data type to send and then unpack the receive buffer directly into the awaiting datastructure. When tested for a single exchange section of code the change did not elicit an improvement in performance. This needs further investigation and closer inspection of list files that can be produced by the compiler detailing where sections of code are optimised.
MPI_Wait conversion to MPI_WaitAny
The existing code forces the receiving task to process the receive buffer in a prescribed order. Profiling indicated a large (almost a quarter) of the runtime was spent in this wait function. We considered changing the MPI_Wait to an MPI_WaitAny call, which allows the receive buffer to be populated in any order. Somewhat surprisingly there was not a significant performance boost here, which should be investigated further.
| ratio of steptime | ratio | reciprocal | Percentage reduction in time |
| Loop Merge/Ref | 0.83532 | 1.197146 | 16.47 |
| Double complex/Ref | 0.98543 | 1.014785 | 1.46 |
| WaitAny/Ref | 0.995143 | 1.00488 | 0.48 |
| AllReduce/Reference | 1.013357 | 0.986819 | -1.33571 |
Table 1: data shows the ratio of time (in seconds) per step for the modified code divided by the time (in seconds per step) for the unmodified code.
In summary, the Leeds Dynamo Code was profiled with Cray PAT (perftools ) on Archer (UK National Supercomputing Service). Several “hot spots” were identified, several code modifications have been suggested and some modifications were trialled. The most promising improvement appears to be the merging of loops in the routines that deal with transforming solution variables between real and spectral space, which alone can provide a substantial performance boost. Further investigation of the other 3 proposed performance enhancements is also desirable in the future.